TD documentation archive in ARCHE
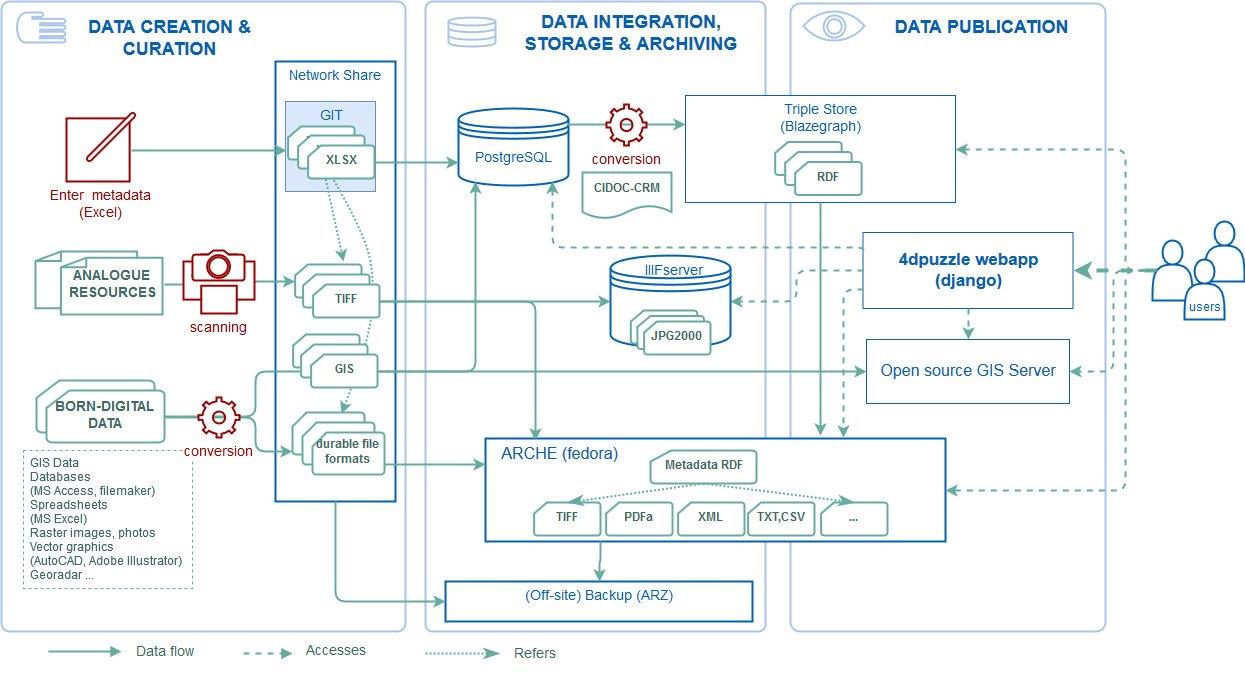
Figure 1: System architecture and workflow.
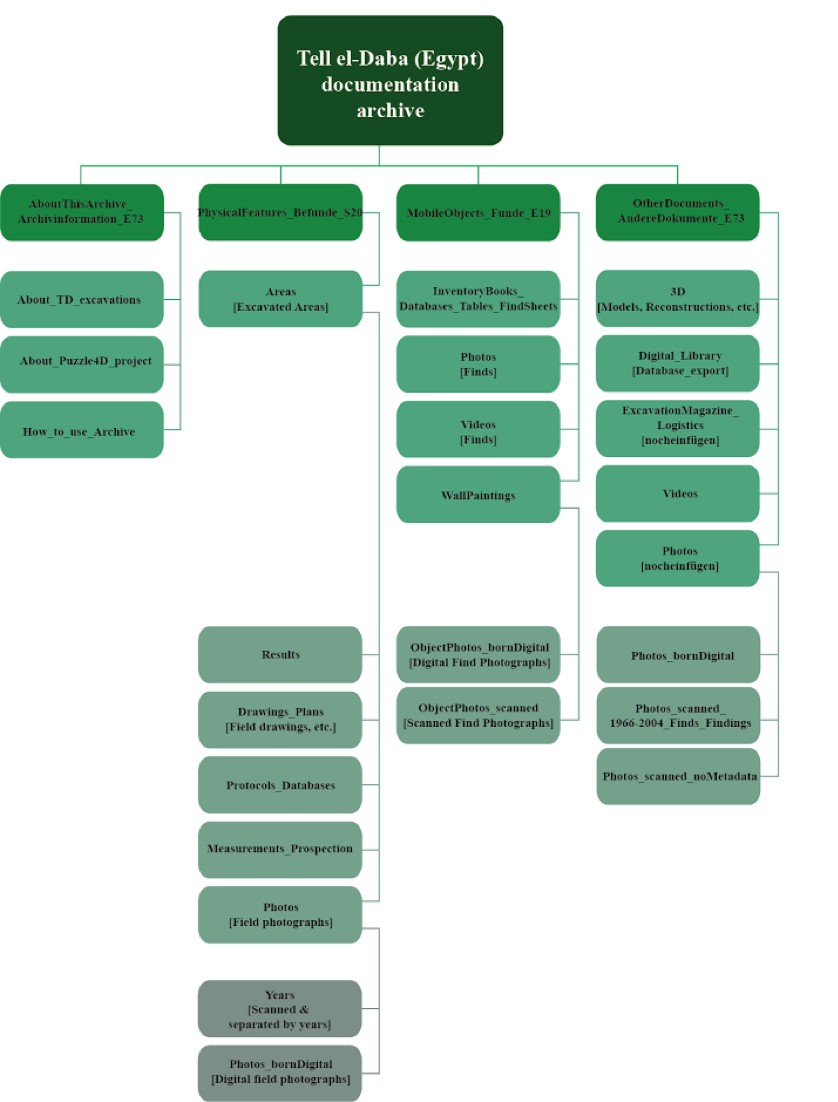 Figure 2: Structure of TD documentation archive.
Figure 2: Structure of TD documentation archive.
All the material processed in the project will be archived in the repository ARCHE. In accordance with OAIS model, ARCHE is not just meant to store the data (Archival Information Package) but also making it available (Dissemination Information Package). Given the access restrictions, most of the digitized resources won’t be publicly available, however at least the structure of the whole collection as well as all the metadata, with important information about the contents of resources, will be accessible. Furthermore, there are additional components of the overall solution that allow alternative ways for exploring the dataset (Figure 1):
- primary entry point and dissemination channel is the web application 4dpuzzle. It has been developed at the ACDH-OeAW based upon the high-level Python Web framework django and a set of custom developed django packages: https://4dpuzzle.orea.oeaw.ac.at/explore/ (test version). The webapp offers a user friendly interface to query and view the project data, serves as a gateway to other data providers (ARCHE, triple store, Geoserver) and provides a rich API to search and retrieve data in different formats (JSON expression of the relational data model; ARCHE-RDF). The webapp is also used to provide information about the project. The code of the webapp is available at https://github.com/acdh-oeaw/4dpuzzle und MIT license.
- scanned images are served via a IIIF server a community standard for image delivery. (http://iiif.io/)
- metadata in CIDOC-CRM is stored in a triple store, allowing exploration for expert users with arbitrarily complex queries using SPARQL query language either through the default blazegraph query interface (https://p4d-rdf.acdh-dev.oeaw.ac.at/#query) or from the 4DP webapp (https://4dpuzzle.orea.oeaw.ac.at/sparql/query/).
- Parallel to the development of the main application, we have experimented with software solutions for querying our metadata triple store via a user-friendly web-interface (Metaphacts, wisKI: http://www.metaphacts.com/, http://wiss-ki.eu/).
ARCHE (https://arche.acdh.oeaw.ac.at) is run by ACDH, was launched in December 2017 and is a repository certified with the CoreTrustSeal. ARCHE is primarily intended to be a service for long term storage of humanities data in Austria. The repository builds on the well-established open-source repository software Fedora Commons version 4 which provides a sound technological basis for implementing the OAIS (Open Archival Information System) reference model by taking care of storage, management and dissemination of our content.
The deposition of the data into ARCHE has been a complex, iterative process, in which the actual ingestion (i.e. uploading data into the system) is only the last part. The two other critical aspects were the creation of metadata compliant to the ARCHE metadata schema (already described in section 1.3.8), and the curation and quality checks regarding filename conventions, formats, consistency of descriptions etc. The quality checks were performed by ARCHE curators with the help of a dedicated script (repo-file-checker). All errors were reported back to the 4DP team with request for corrections. After corrections were either applied manually or automated with scripts, the quality checks were executed again by the ARCHE. These iterations were repeated until no errors occurred.
Given the sheer size of the dataset and a number of external factors this curation and ingestion process ran over most of 2019, first test ingest with resources from F-I performed in the beginning of 2019. The actual ingest of TD data and prepared metadata is done by the ARCHE team, while the 4DP team remains available for questions and any required feedback. The final ingest of over 122000 files with overall volume of around 9.6 TB will start in January 2020, but it will take time and may need time after the end of the month when 4DP project finishes.
The TD documentation archive is available at https://id.acdh.oeaw.ac.at/td-archiv and it will also persistently referenceable with the handle http://hdl.handle.net/21.11115/0000-000C-4F1C-E.
Data in the TD documentation archive is structured according to the contents of documents, containing four main folders related to 1. Documents with information about the TD documentation archive (AboutThisArchive_Archivinformation_E73), 2. Documents about field evidence (PhysicalFeatures_Befunde_S20) , 3. Documents about finds (MobileObjects_Funde_E19) and 4. other documentation, either related to both, finds and field evidence or to other types of documents, e.g. literature, 3D models, and photos without file level metadata pertaining to both, field evidence and finds (OtherDocuments_AndereDokumente_E73).