Metadata concepts and workflow
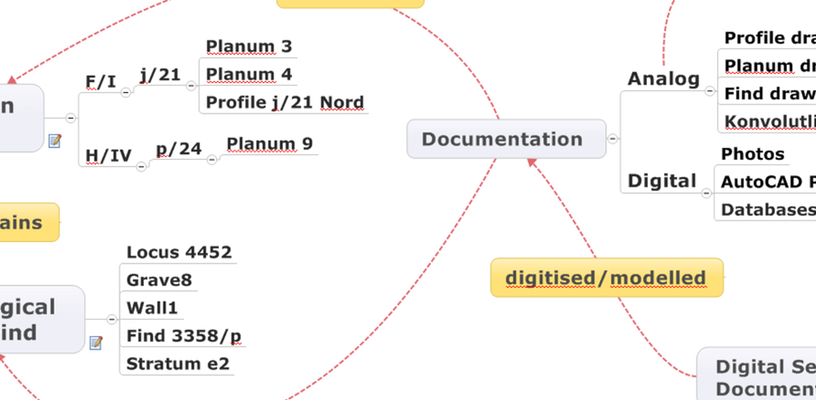
Figure 1: Main categories of physical reality, documentation and digitising processes.
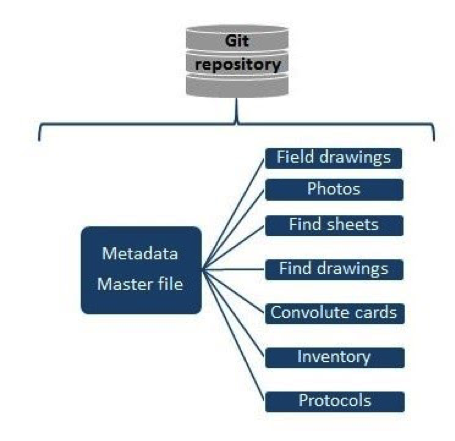 Figure 2: Metadata created for TD resources and documented object.
Figure 2: Metadata created for TD resources and documented object.
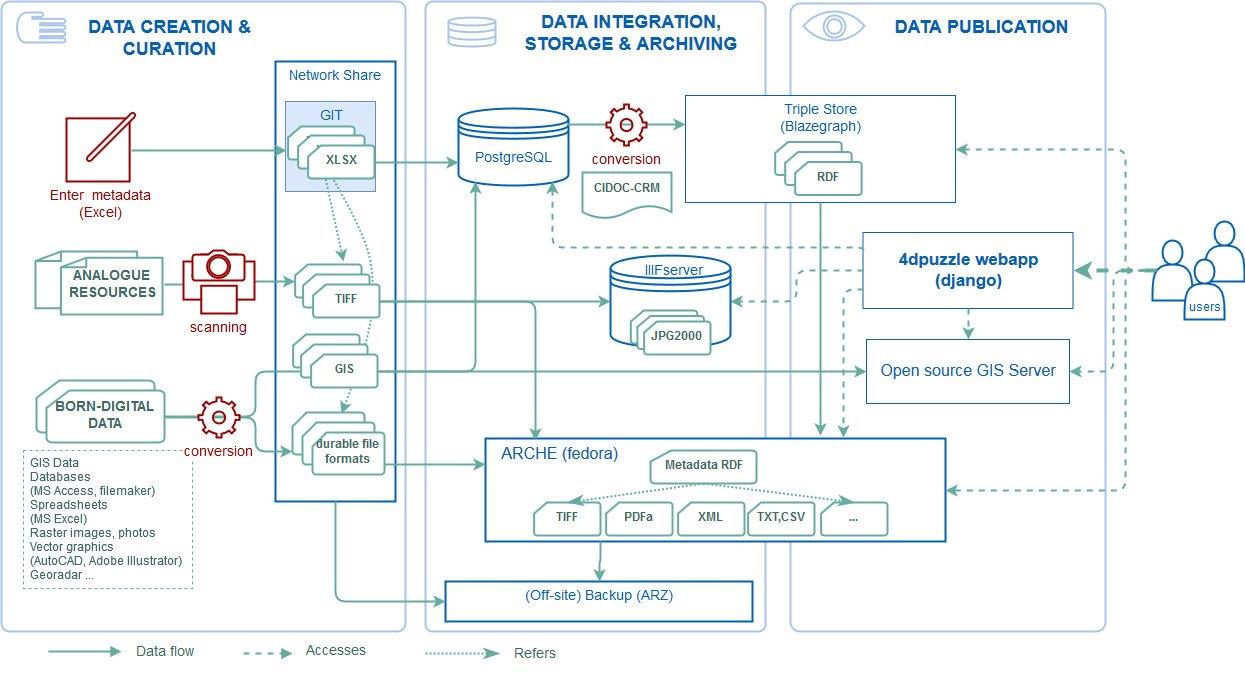 Figure 3: System architecture and workflow.
Figure 3: System architecture and workflow.
The 4DP metadata model distinguishes five main categories distinct in their nature: excavation areas, archaeological features and finds, documentation (analogue & digital), physical storage and digital secondary documentation (Figure 1).
In very simple terms it can be said that the physical reality of archaeological features and finds (including archaeological objects, i.e. buildings, graves, pottery created in the distant past that were found in specific excavation areas (excavation objects such as squares and areas created by the archaeologists in the not so distant past) are documented in analogue and digital documentation. This documentation, which is stored in either physical archives (OREA or archive in Cairo) or digitally on the OREA network drive (‘TD Archive’ folder) is digitised (if analogue) or prepared for digital preservation (if born-digital) in the Puzzle 4D project.
Consequently, the 4DP metadata contains the following types of information:
- Information on file: filename, -identifier, -title
- Description of documentation (analogue or born-digital): e.g. document type, creator, creation date/excavation season, physical/digital storage, comments
- Information on archaeological context (physical reality): e.g. excavation objects, archaeological objects, finds
- Information on digitisation and/or preparation for digital long-term archiving: e.g. scanner, creator of scan and metadata, comments, etc.
- Information on access and copyright
Metadata fields were reviewed in 2017 (for midterm evaluation) and fields that were not important or redundant were removed.
We chose spreadsheets (MS Excel) for the metadata entry and management of the controlled vocabularies (Figure 2). The metadata master file contained metadata of physical objects such as excavation objects, archaeological objects, finds, bulk finds (convolutes, animal bones, stone registry), locus, stratum/phase. 4DPuzzle identifiers (for archaeological objects and finds without TD inventory numbers) and a list of terms to specify types of archaeological objects (for data entry) are included in the metadata master file. Identifiers for physical objects relate the resource files to the metadata master file.
We found the flexibility offered by MS Excel was an advantage compared to other systems which would need development of a user interface or customisation of an existing interface to accommodate the needs of the project. Another big advantage is that users are accustomed to this default piece of office software. After defining the main categories of the data structure and creating an identifier policy we could immediately start the metadata entry process. Furthermore, Excel allows to enter values quickly (e.g. entering the same value to many cells at the same time, where a database only allows to enter one value at a time), which was another important argument to stick with Excel.
Disadvantages are that this method is more prone to errors, as identifier handling and management is performed by humans and requires constant monitoring and regular quality assessment. Quality control took place when data from the spreadsheets was further processed, creating the Knowledge Graph and ingesting into the 4DP webapp, which helped to identify errors and inconsistencies in data entries. Several rounds of corrections were required, however, we still think that this workflow allowed to process a larger amount of resources than we would have been able to handle with entering data in a database via an entry form, where data entry would have been much slower, let alone the substantial amount of work that would be needed to develop such a bespoke database application. Only few students were involved in data entry and they became experts in TD documentation and were also able to correct any mistakes quickly.
The mappings of the metadata spreadsheets to CIDOC CRM created a knowledge graph, making explicit the individual entities and the relations between them. This knowledge graph represented in RDF (Resource Description Framework;) was ingested into a triple store (Blazegraph, https://blazegraph.com/). Relations between the resources are either established on the class level (because they belong to the same CIDOC CRM class, e.g. “document” or “physical thing”), on the SKOS concept level (because the same thesaurus term was attributed to them, e.g. “field drawing”) or on an instance level (because they describe the same excavation area or archaeological feature/find, e.g. “Site TD, Area F/1, SQUARE j/21, Planum 3”).
Workflow from metadata entry to integrated web application
The actual final workflow from the metadata to an integrated web application with all metadata and digitized objects integrated and searchable involves a number of components (Figure 3):
- Metadata creation/curation via interlinked MS Excel spreadsheets (Figure 2).
- The manually maintained/created spreadsheets containing the metadata are imported into a PostgreSQL database with PostGIS extension allowing to model and store GIS objects. This import script can either be run in predefined frequencies (cron job) or triggered manually.
- The data in the PostgreSQL database is made accessible through a user friendly (python/django based) web application (https://4dpuzzle.orea.oeaw.ac.at/explore), which represents the primary entry point to all digital data of the project.
- The Karma models are applied to the spreadsheets and the generated RDF (modelled in CIDOC-CRM) is ingested into the triple store. The main goal of this transformation is to provide a standard-conformant serialization of the data and a versatile querying capability via SPARQL, which allows for any custom advanced queries on the dataset represented in a semantic conceptual model, beyond the querying functionality offered by the default application. In future RDFs will be generated from the PostgresSQL database application, to reflect changes made in the web application.
- The actual binary data, i.e. the scans resided during the curation process on a file server (see 1.2.10) and are stored in a format which meets all requirements for longterm archiving (TIFF, no compression). Representations of the binaries suitable for a presentation in the context of a website are provided through ARCHE’s dissemination services and integrated into the 4dpuzzle-website.
- Metadata dumps from the triple store together with the binary files (digitized objects) are imported into ARCHE. The repository provides its own generic search and browse capabilities, thus it represents an alternative mode of access to the data.
- Metadata entries browsable in https://4dpuzzle.orea.oeaw.ac.at/explore are back-linked to the corresponding objects in ARCHE.
- GIS Data has been published following the WMS and WFS protocols (via Qgis Server) which allows the data integration through third party tools (like QGIS). A basic view on the Data is integrated into 4dpuzzle-website.